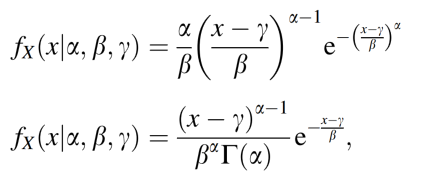Summary:
T2distribution(:,1)=[]
T2distri=T2distribution
T2row1=T2distri(1,:)
T2row2=T2distri(2,:)
T2row3=T2distri(3,:)
T2row4=T2distri(4,:)
subplot(2,2,1)
area(T2row1)
subplot(2,2,2)
area(T2row2)
subplot(2,2,3)
area(T2row3)
subplot(2,2,4)
area(T2row4)

The following are two kind of fitting functions.
1.
General model Fourier3:
f(x) = a0 + a1*cos(x*w) + b1*sin(x*w) +
a2*cos(2*x*w) + b2*sin(2*x*w) + a3*cos(3*x*w) + b3*sin(3*x*w)
where x is normalized by mean 32.5 and std 18.62
Coefficients (with 95% confidence bounds):
a0 = 0.0007262 (0.0006442, 0.0008081)
a1 = 0.0002028 (3.608e-05, 0.0003696)
b1 = -0.0009519 (-0.001061, -0.0008427)
a2 = -0.0006422 (-0.0007004, -0.000584)
b2 = -0.0003332 (-0.000459, -0.0002074)
a3 = -0.0001401 (-0.0002752, -4.879e-06)
b3 = -1.008e-05 (-5.636e-05, 3.62e-05)
w = 1.857 (1.655, 2.059)
Goodness of fit:
SSE: 9.065e-07
R-square: 0.9812
Adjusted R-square: 0.9789
RMSE: 0.0001272

2.
General model Weibull:
f(x) = a*b*x^(b-1)*exp(-a*x^b)
Coefficients (with 95% confidence bounds):
a = 0.001374 (-0.0002114, 0.00296)
b = 0.8532 (0.5792, 1.127)
Goodness of fit:
SSE: 4.666e-05
R-square: 0.03477
Adjusted R-square: 0.0192
RMSE: 0.0008675

As shown in the figure, the single Weibull is not effective for fitting. In contrast, the Fourier of 3 terms is effective.
Tomorrow, I will continue to find more effective functions for fitting.