Today, I had some problems with IP.
Summary:
I found that I cannot load some data, such as at10 and at90, of well 2 from original files to IP. I asked Pratiksha, and she recommends me to move version 4.4.2017 to 4.4.2016. So I sent and email to ipsupport. They sent me the link of the old version. But after installing it, I cannot even open the software.
I will continue to communicate with them and solve the problem as soon as possible.
Tomorrow, I will try to solve the problem and start to deal with the data of well 2 and BHP.
5/31/2017
5/30/2017
k-nearest neighbor classification
Today, I read materials about k-nearest neighbor classification algorithm.
Summary:
In last Thursday's group meeting, I was asked the iteration times of KNN in my paper. I remembered that I did not set it in my codes. Today, I look into it and read some materials online.
Actually, KNN does not need to set iteration times. The reasons are as follows.
In KNN model, first we set k, for example k=3. Then, we select 80% of all data to train the model. When training the model, 3 points are selected randomly first. all other points are used to calculate the distance between them and classified into the one which has the nearest distance to be the same cluster. Then the sum of all distances are compared. After calculating all possible conditions, we can obtain the smallest one, so the model is built. As a result, there is no need to set iteration times because we do not iterate. Instead, we have the goal function and we can get the global minimum, namely the smallest distance.
So what is the difference between ANN and KNN? I think one big difference is that for ANN, every time you train an ANN model, they will not be exactly the same. But for KNN, as long as you have the same k value and same training data, you will obtain exactly the same model with enough calculations.
Tomorrow, I will continue to read more about my research and discuss with you about future work.
Summary:
In last Thursday's group meeting, I was asked the iteration times of KNN in my paper. I remembered that I did not set it in my codes. Today, I look into it and read some materials online.
Actually, KNN does not need to set iteration times. The reasons are as follows.
In KNN model, first we set k, for example k=3. Then, we select 80% of all data to train the model. When training the model, 3 points are selected randomly first. all other points are used to calculate the distance between them and classified into the one which has the nearest distance to be the same cluster. Then the sum of all distances are compared. After calculating all possible conditions, we can obtain the smallest one, so the model is built. As a result, there is no need to set iteration times because we do not iterate. Instead, we have the goal function and we can get the global minimum, namely the smallest distance.
So what is the difference between ANN and KNN? I think one big difference is that for ANN, every time you train an ANN model, they will not be exactly the same. But for KNN, as long as you have the same k value and same training data, you will obtain exactly the same model with enough calculations.
Tomorrow, I will continue to read more about my research and discuss with you about future work.
5/26/2017
improve the draft
Today, I improved the draft.
Summary:
I sent to your email. Please improve our first paper on the final version. Thank you.
Next week, I will start to work on the second well.
Summary:
I sent to your email. Please improve our first paper on the final version. Thank you.
Next week, I will start to work on the second well.
5/25/2017
finish writing the draft
Today, I finish writing the draft.
Summary:
I send to your email.
Tomorrow, I will see if I can improve it a little first and send you the final draft.
Summary:
I send to your email.
Tomorrow, I will see if I can improve it a little first and send you the final draft.
5/24/2017
change the conclusion and validate SCG algorithm
Today, I change the conclusion of the paper and validate SCG algorithm.
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=19fe5f27557024765b9ff270e05350f07&authkey=Adju90qODE0EXA9wZfYELe4&expiration=2017-06-24T02%3a57%3a59.000Z
Tomorrow, I will try to finish writing the draft of the paper.
There are four more things to do:
add time comparison of two models
describe two models more clearly
validate why two hidden layers are enough
change the parts marked in the draft and improve it as a whole
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=19fe5f27557024765b9ff270e05350f07&authkey=Adju90qODE0EXA9wZfYELe4&expiration=2017-06-24T02%3a57%3a59.000Z
Tomorrow, I will try to finish writing the draft of the paper.
There are four more things to do:
add time comparison of two models
describe two models more clearly
validate why two hidden layers are enough
change the parts marked in the draft and improve it as a whole
5/23/2017
change part 4 and replot some figures
Today, I change case study part and replot some figures.
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=1cce2e6bb5da248a9ad918981682a61f5&authkey=AQ5bCbp4RNDMdyknCryezXg&expiration=2017-06-22T22%3a47%3a55.000Z
Tomorrow, I will prepare for the team presentation and continue to write the paper.
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=1cce2e6bb5da248a9ad918981682a61f5&authkey=AQ5bCbp4RNDMdyknCryezXg&expiration=2017-06-22T22%3a47%3a55.000Z
Tomorrow, I will prepare for the team presentation and continue to write the paper.
5/22/2017
change the first three parts of the paper
Today, I changed the first three parts of the paper, abstract, introduction and theory and methodology.
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=1f18fbeba17a14cf3a1ee81e43a444edb&authkey=AdMw5EOlC6su47n2cc91S98&expiration=2017-06-21T23%3a04%3a18.000Z
Tomorrow, I will continue to write the paper.
Summary:
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=1f18fbeba17a14cf3a1ee81e43a444edb&authkey=AdMw5EOlC6su47n2cc91S98&expiration=2017-06-21T23%3a04%3a18.000Z
Tomorrow, I will continue to write the paper.
5/12/2017
start writing the second paper
Today, I start writing the second paper.
Summary:
I write on the basis of the first paper.
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=126f7ead71e7f4029bf7337dce2d7b182&authkey=AfYDBhA9NZZVE2ApappYOpE&expiration=2017-06-11T22%3a25%3a12.000Z
Should we add the second paper into the first one to obtain a more complete paper or we separate them into two papers? The second paper may be even shorter than the first one. We can discuss it when we meet next time.
Summary:
I write on the basis of the first paper.
https://sooners-my.sharepoint.com/personal/jiabo_he_ou_edu/_layouts/15/guestaccess.aspx?docid=126f7ead71e7f4029bf7337dce2d7b182&authkey=AfYDBhA9NZZVE2ApappYOpE&expiration=2017-06-11T22%3a25%3a12.000Z
Should we add the second paper into the first one to obtain a more complete paper or we separate them into two papers? The second paper may be even shorter than the first one. We can discuss it when we meet next time.
5/10/2017
Find some conferences and journals
Today, I found some conferences and journals which may be suitable for our paper.
Summary:
Summary:
Conferences:
SPE Canada
Heavy Oil Technical Conference
SPE Canada
Unconventional Resources Conference
Offshore
Technology Conference Asia (OTC Asia)
IADC/SPE
Drilling Conference and Exhibition
Journals:
SPWLA Petrophysics
Journal (0.514)
SPE Journal
(1.442)
SPE
Production & Operations (0.818)
SPE
Reservoir Evaluation & Engineering (1.767)
Journal of Petroleum
Science and Engineering (1.655)
Energy
Sources Part A (0.455)
Geophysical
Prospecting (1.835)
Energy &
Fuels (2.835)
The number is the impact factor. The red ones are my preference.
Could we discuss about which are the best for our submission tomorrow? Could you please give me some recommendations? Thank you so much.
5/08/2017
finish the comparison part
Today, I finish the comparison part.
Summary:

Since there are only 4000 words now in our paper with this part, I wonder if it is too short to be accepted by a Journal. Is it enough work for now for our paper to be published? If you think it is ok, we may look for and discuss where to submit our paper. If not, we can discuss how to improve our paper. Also, we may look for some conference to submit our abstract.
On Wednesday, I plan to look for some Journals and Conferences suitable for our paper and discuss with you about them and our paper.
Summary:

Since there are only 4000 words now in our paper with this part, I wonder if it is too short to be accepted by a Journal. Is it enough work for now for our paper to be published? If you think it is ok, we may look for and discuss where to submit our paper. If not, we can discuss how to improve our paper. Also, we may look for some conference to submit our abstract.
On Wednesday, I plan to look for some Journals and Conferences suitable for our paper and discuss with you about them and our paper.
5/05/2017
Comparison of R and MATLAB for training a model
Today, I make comparison of R and MATLAB for training a model.
Summary:

Next week, I will add them into the paper.
Summary:

Next week, I will add them into the paper.
5/04/2017
similar time, worse prediction
Today, I build an ANN model in r exactly the same as what it is in matlab. But the prediction result is much worse than that in matlab.
Summary:
I build an ANN model with same hidden layers and neurons, same training function (scg), same initial weights and biases (0.1), same training (85%) and testing (15%) data.
The result shows that in matlab, the time for 500 iterations is 2.68 s, while in r, the time for 500 iterations is 2.53 s. It seems that r is even a little better. (I was wrong because I did not control the same training function.)
However, the prediction result of the ANN model in r is very poor, which is shown below.
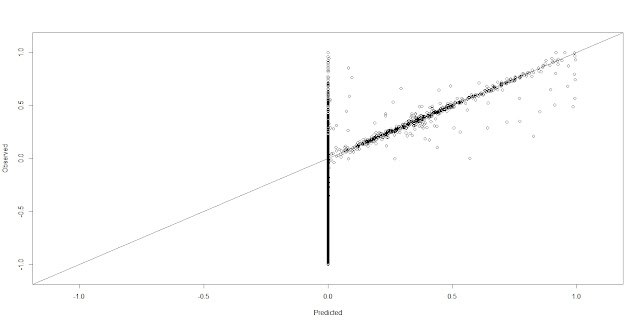 For most data, the prediction result is about 0 no matter what it is originally. For now, I do not know why it is like that.
For most data, the prediction result is about 0 no matter what it is originally. For now, I do not know why it is like that.
Tomorrow, I will try to fix the problem.
Summary:
I build an ANN model with same hidden layers and neurons, same training function (scg), same initial weights and biases (0.1), same training (85%) and testing (15%) data.
The result shows that in matlab, the time for 500 iterations is 2.68 s, while in r, the time for 500 iterations is 2.53 s. It seems that r is even a little better. (I was wrong because I did not control the same training function.)
However, the prediction result of the ANN model in r is very poor, which is shown below.

Tomorrow, I will try to fix the problem.
5/03/2017
Build an ANN model in R
Today, I try to build an ANN model in R, but I have not finished it.
Summary:
I find the basic ANN model function in R.
I start to set every parameter the same in R.
Now I am trying to find the same training function, scaled conjugate gradient function, but i do not find it.
Tomorrow, I will continue to adjust the model.
Summary:
I find the basic ANN model function in R.
I start to set every parameter the same in R.
Now I am trying to find the same training function, scaled conjugate gradient function, but i do not find it.
Tomorrow, I will continue to adjust the model.
5/02/2017
Finish the draft
Today, I finish the draft.
Summary:
I sent you by the email.
Tomorrow, I will start to compare R and Matlab.
Summary:
I sent you by the email.
Tomorrow, I will start to compare R and Matlab.
5/01/2017
Finish the case study
Today, I finish the case study part.
Summary:
https://1drv.ms/w/s!Ao543UQvyvOWjFGXAiwi6homt05n
Tomorrow, I will finish all the draft.
Summary:
https://1drv.ms/w/s!Ao543UQvyvOWjFGXAiwi6homt05n
Tomorrow, I will finish all the draft.
Subscribe to:
Comments (Atom)