Today, I replotted the figures and build method 2
Summary:
I will send you by the email.
Next week, I will build method 3 and start to write the second paper.
7/27/2017
plot figures and tables in the outline
Today, I plotted figures and tables in the outline.
Summary:
I will send you by the email.
Tomorrow, I will finish plotting figures and tables for one well in three methods.
Summary:
I will send you by the email.
Tomorrow, I will finish plotting figures and tables for one well in three methods.
7/26/2017
design the distribution examples of flags
Today, I designed the distribution examples of flags.
Summary:
I will send you by the email.
Tomorrow, I will continue to build the three models for one well.
Summary:
I will send you by the email.
Tomorrow, I will continue to build the three models for one well.
7/25/2017
finish preparing for the results of the second paper
Today, I finished preparing for the results of the second paper.
Summary:
I will send you by the email.
Tomorrow, I may start to write the second paper.
Summary:
I will send you by the email.
Tomorrow, I may start to write the second paper.
7/24/2017
finish the task of abernathy well
Today, I follow your instructions to compare the three wells and finish the abernathy well.
Summary:
I have finished the abernathy well. I will send it to your by email.
Tomorrow, I will finish compare the rest two wells.
Summary:
I have finished the abernathy well. I will send it to your by email.
Tomorrow, I will finish compare the rest two wells.
7/21/2017
do some data preprocessing to improve the model
Today, I did not figure out how to improve the model. I just delete 66/4359 outliers to obtain a slightly better result.
Summary:
First, I changed the order of predicting these 8 outputs. I changed the order of perm 4 and perm 3 so that both orders of cond and perm are 2134, which is more reasonable. 8 changed models are shown as follows.
ANN1: log data to cond 2;
ANN2: log data + cond 2 to cond 1;
ANN3: log data + cond 2 1 to cond 3;
ANN4: log data + cond 2 1 3 to cond 4;
ANN5: log data + cond 2 1 3 4 to perm 2;
ANN6: log data + cond 2 1 3 4 + perm 2 to perm 1;
ANN7: log data + cond 2 1 3 4 + perm 2 1 to perm 3;
ANN8: log data + cond 2 1 3 4 + perm 2 1 3 to perm 4.
The result improved 8 R2 of testing data in the above order are 0.91, 0.92, 0.88, 0.87, 0.71, 0.70, 0.65, 0.61 in the above order.
5 of them are higher, 2 of them are the same and just 1 is lower, which is perm 4.
For now, I predict 1 output and add predicted values into next model's inputs to train and test the next model. I plan to build all eight models with original data first and use predicted data to calculate the outputs directly next week. I think it may help.
Next week, I plan to do as the above idea.
Summary:
First, I changed the order of predicting these 8 outputs. I changed the order of perm 4 and perm 3 so that both orders of cond and perm are 2134, which is more reasonable. 8 changed models are shown as follows.
ANN1: log data to cond 2;
ANN2: log data + cond 2 to cond 1;
ANN3: log data + cond 2 1 to cond 3;
ANN4: log data + cond 2 1 3 to cond 4;
ANN5: log data + cond 2 1 3 4 to perm 2;
ANN6: log data + cond 2 1 3 4 + perm 2 to perm 1;
ANN7: log data + cond 2 1 3 4 + perm 2 1 to perm 3;
ANN8: log data + cond 2 1 3 4 + perm 2 1 3 to perm 4.
The result improved 8 R2 of testing data in the above order are 0.91, 0.92, 0.88, 0.87, 0.71, 0.70, 0.65, 0.61 in the above order.
5 of them are higher, 2 of them are the same and just 1 is lower, which is perm 4.
For now, I predict 1 output and add predicted values into next model's inputs to train and test the next model. I plan to build all eight models with original data first and use predicted data to calculate the outputs directly next week. I think it may help.
Next week, I plan to do as the above idea.
7/20/2017
predict 8 outputs one by one to get better results
Today, I predicted 8 outputs one by one to get a better result than predicting them together.
Summary:
The following two methods are inspired from honoring relationship between 4 cond and 4 perm.
First, I build two models. The first is to use log data to predict 4 cond. The second is to use 4 cond to predict 4 perm.
The prediction accuracy of 4 cond is good, 4 R2 of testing data are 0.80, 0.90, 0.86, 0.86.
But using 4 predicted cond to predict 4 perm is not good. 4 R2 of testing data are 0.54, 0.65, 0.56, 0.47.
Second, I build eight models.
I predict 8 outputs together first for ten times and average the R2 results. The accuracy from top to bottom is cond 2 1 3 4 and perm 2 1 4 3.
ANN1: log data to cond 2;
ANN2: log data + cond 2 to cond 1;
ANN3: log data + cond 2 1 to cond 3;
ANN4: log data + cond 2 1 3 to cond 4;
ANN5: log data + cond 2 1 3 4 to perm 2;
ANN6: log data + cond 2 1 3 4 + perm 2 to perm 1;
ANN7: log data + cond 2 1 3 4 + perm 2 1 to perm 4;
ANN8: log data + cond 2 1 3 4 + perm 2 1 4 to perm 3.
The result improved. 8 R2 of testing data in the above order are 0.89, 0.91, 0.88, 0.87, 0.71, 0.64, 0.64, 0.65.
Tomorow, I will see if I can improve prediction accuracy by other methods.
Summary:
The following two methods are inspired from honoring relationship between 4 cond and 4 perm.
First, I build two models. The first is to use log data to predict 4 cond. The second is to use 4 cond to predict 4 perm.
The prediction accuracy of 4 cond is good, 4 R2 of testing data are 0.80, 0.90, 0.86, 0.86.
But using 4 predicted cond to predict 4 perm is not good. 4 R2 of testing data are 0.54, 0.65, 0.56, 0.47.
Second, I build eight models.
I predict 8 outputs together first for ten times and average the R2 results. The accuracy from top to bottom is cond 2 1 3 4 and perm 2 1 4 3.
ANN1: log data to cond 2;
ANN2: log data + cond 2 to cond 1;
ANN3: log data + cond 2 1 to cond 3;
ANN4: log data + cond 2 1 3 to cond 4;
ANN5: log data + cond 2 1 3 4 to perm 2;
ANN6: log data + cond 2 1 3 4 + perm 2 to perm 1;
ANN7: log data + cond 2 1 3 4 + perm 2 1 to perm 4;
ANN8: log data + cond 2 1 3 4 + perm 2 1 4 to perm 3.
The result improved. 8 R2 of testing data in the above order are 0.89, 0.91, 0.88, 0.87, 0.71, 0.64, 0.64, 0.65.
Tomorow, I will see if I can improve prediction accuracy by other methods.
7/19/2017
read papers about cole-cole equation and debye equation
Today, I read papers about cole-cole equation and debye equation.
Smuuary:
cole-cole equation and debye equation are highly related.
The first equation is cole-cole equation. the second is debye equation, when alpha=0, cole-cole equation becomes debye equation.
the third is the real part permittivity equation, the fourth is the imaginary part permittivity equation. they are all functions of w.

I think i can obtain all other constants of the third and fourth equations so that I can know the relationship between real part permittivity and w, imaginary part permittivity and w. They may help me improve the prediction accuracy.
Tomorrow, I will try and validate this method.
Smuuary:
cole-cole equation and debye equation are highly related.
The first equation is cole-cole equation. the second is debye equation, when alpha=0, cole-cole equation becomes debye equation.
the third is the real part permittivity equation, the fourth is the imaginary part permittivity equation. they are all functions of w.

I think i can obtain all other constants of the third and fourth equations so that I can know the relationship between real part permittivity and w, imaginary part permittivity and w. They may help me improve the prediction accuracy.
Tomorrow, I will try and validate this method.
7/18/2017
Finish changing the paper
Today, I finished changing the first paper.
Summary:
I emailed to you with the draft.
Tomorrow, I will continue to focus on my second research.
Summary:
I emailed to you with the draft.
Tomorrow, I will continue to focus on my second research.
7/17/2017
Improve the first paper
Today, I improved the first paper following Yifu's instructions.
Summary:
I changed part of the paper. I will finish it tomorrow. Yifu told me to add some contents in the paper and change all colored figures into black-and-white ones, which is time-consuming.
Tomorrow, I will continue to change the paper.
Summary:
I changed part of the paper. I will finish it tomorrow. Yifu told me to add some contents in the paper and change all colored figures into black-and-white ones, which is time-consuming.
Tomorrow, I will continue to change the paper.
7/14/2017
think about the physical relationship between cond and perm
Today, I think about the physical relationship between cond and perm and why it is more accurate to predict magnitude and phase than cond and perm.
Summary:
 Next week, I will see if I can find a better explanation.
Next week, I will see if I can find a better explanation.
Summary:

7/13/2017
verify the method in 'at land state' well
Today, I verify the method in 'at land state' well.
Summary:
I also changed original cond and perm into magnitude and phase in 'at land state' well to get a good prediction result.
The first is the prediction performance of magnitude. R2 of testing data are 0.91, 0.87, 0.80, 0.68.

The second is the prediction performance of phase. R2 of testing data are 0.87, 0.93, 0.88, 0.82.

Tomorrow, I will compare all inputs to know better about their effects on prediction performance.
Summary:
I also changed original cond and perm into magnitude and phase in 'at land state' well to get a good prediction result.
The first is the prediction performance of magnitude. R2 of testing data are 0.91, 0.87, 0.80, 0.68.

The second is the prediction performance of phase. R2 of testing data are 0.87, 0.93, 0.88, 0.82.

Tomorrow, I will compare all inputs to know better about their effects on prediction performance.
7/12/2017
Use magnitude and phase to improve the result
Today, I read some papers and decide to use magnitude and phase again.
Summary:
There are some papers which predict magnitude and phase of one value like permittivity. So I think it may be helpful. After applying this method into abernathy data, the accuracy of prediction improves a lot.
The first is the prediction result for magnitude. R2 of testing data are 0.93, 0.91, 0.88, 0.77.

The second is the prediction result for phase. R2 of the testing data are 0.85, 0.94, 0.91, 0.88.
 I think the accuracy now is enough for publication.
I think the accuracy now is enough for publication.
Tomorrow, I will continue to read papers if you can give me some time.
Summary:
There are some papers which predict magnitude and phase of one value like permittivity. So I think it may be helpful. After applying this method into abernathy data, the accuracy of prediction improves a lot.
The first is the prediction result for magnitude. R2 of testing data are 0.93, 0.91, 0.88, 0.77.
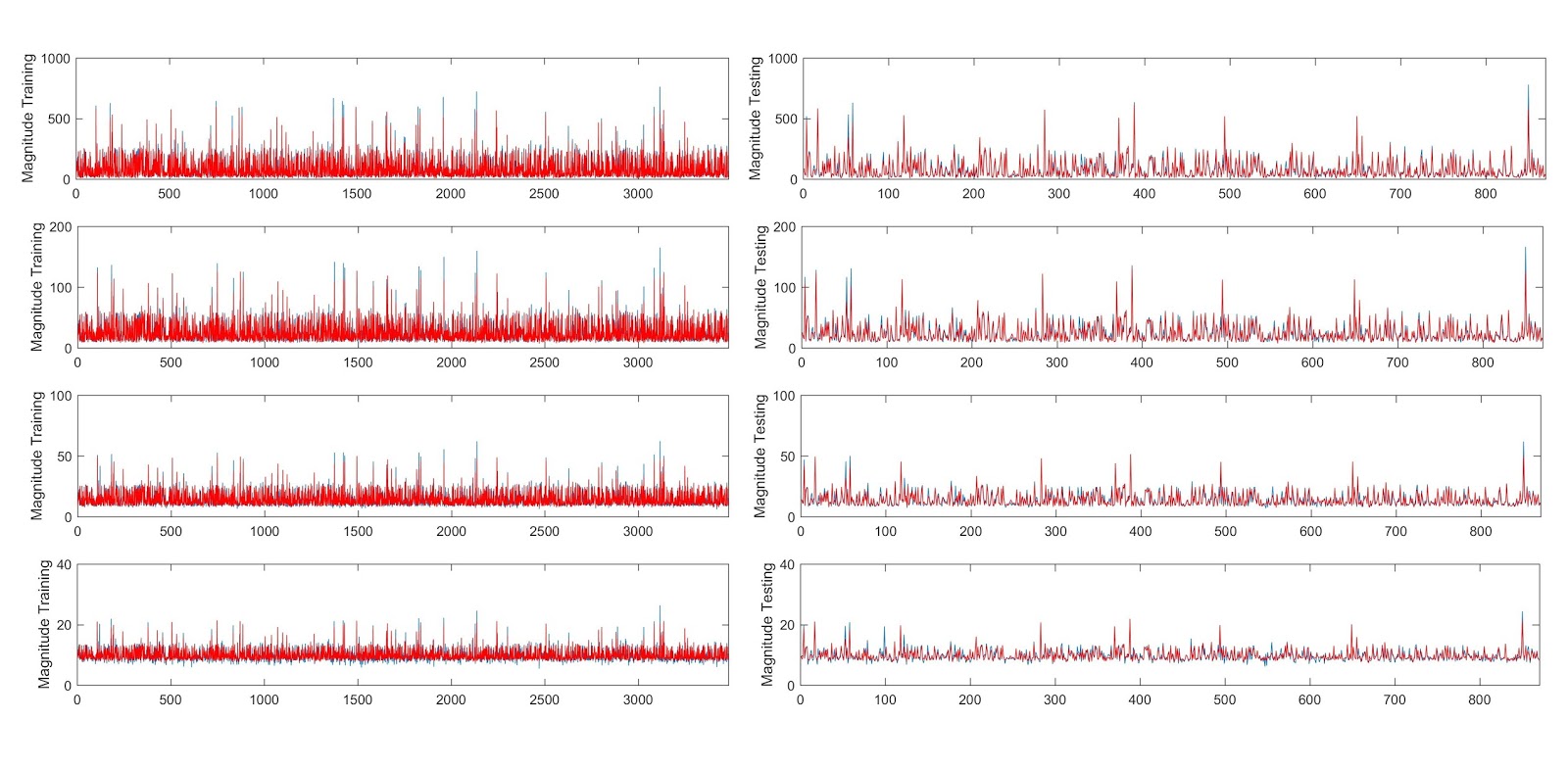
The second is the prediction result for phase. R2 of the testing data are 0.85, 0.94, 0.91, 0.88.

Tomorrow, I will continue to read papers if you can give me some time.
7/11/2017
read some papers
Today, I read some papers, but I cannot find something helpful to use the relationship among frequency, conductivity and permittivity creatively.
Summary:
one method to predict permittivity is:
1. simulate magnitude and phase with FDTD (imputs are real and imaginary part of permittivity)
2. use magnitude and phase as inputs and permittivity as outputs to train the ANN model
3. measure other magnitudes and phases of different materials
4. use data from step 3 and model from step 2 to predict permttivity
another method to predict permittivity is:
1. obtain inputs from elementary measurements
2. build functions of permittivity and locations (linear, quadratic and Gaussian function) for different samples
3. train an ANN model with locations as inputs and parameters of functions as outputs.
4. input other locations to the model and predict permittivity
5. obtain 2-D complex permittivity profiles
FDTD (Finite-difference time-domain method) is a numerical analysis technique used for modeling computational electrodynamics.
Summary:
one method to predict permittivity is:
1. simulate magnitude and phase with FDTD (imputs are real and imaginary part of permittivity)
2. use magnitude and phase as inputs and permittivity as outputs to train the ANN model
3. measure other magnitudes and phases of different materials
4. use data from step 3 and model from step 2 to predict permttivity
another method to predict permittivity is:
1. obtain inputs from elementary measurements
2. build functions of permittivity and locations (linear, quadratic and Gaussian function) for different samples
3. train an ANN model with locations as inputs and parameters of functions as outputs.
4. input other locations to the model and predict permittivity
5. obtain 2-D complex permittivity profiles
FDTD (Finite-difference time-domain method) is a numerical analysis technique used for modeling computational electrodynamics.
7/10/2017
select some depths and get better results
Today, I select some depths and get better results.
Summary:
There are 6731 depths I use as training and testing data last week. They are from 6890 ft to 10255 ft. Today, I tried several times and select depths from 7840 ft to 10019 ft. They are more similar to each other according to lithology. Actually, I get better results from them.
The following is the prediction result of 4 con. They are predicted by 15 logging data. R2 of 4 con are 0.91, 0.90, 0.88 and 0.85, which are very high.

The following is the prediction result of 4 per. They are predicted by 15 logging data and predicted 4 con just now. R2 of 4 per are 0.66, 0.69, 0.61 and 0.62. Although they are not as high as 4 con's. But they are better than last week's results.

Tomorrow, I will try other methods to improve the prediction performance.
Summary:
There are 6731 depths I use as training and testing data last week. They are from 6890 ft to 10255 ft. Today, I tried several times and select depths from 7840 ft to 10019 ft. They are more similar to each other according to lithology. Actually, I get better results from them.
The following is the prediction result of 4 con. They are predicted by 15 logging data. R2 of 4 con are 0.91, 0.90, 0.88 and 0.85, which are very high.

The following is the prediction result of 4 per. They are predicted by 15 logging data and predicted 4 con just now. R2 of 4 per are 0.66, 0.69, 0.61 and 0.62. Although they are not as high as 4 con's. But they are better than last week's results.

Tomorrow, I will try other methods to improve the prediction performance.
7/07/2017
continue to change the paper
Today, I continue to change the paper.
Summary:
I will send you by email once I finish today.
Next week, I will focus on improving the prediction performance of abernathy well.
Summary:
I will send you by email once I finish today.
Next week, I will focus on improving the prediction performance of abernathy well.
7/06/2017
change the first paper
Today, I change the first paper.
Summary:
I spend all day to change the first paper but I has not finished it yet. I will try to finish it tomorrow.
Tomorrow, I will finish changing the paper and send it to you.
Summary:
I spend all day to change the first paper but I has not finished it yet. I will try to finish it tomorrow.
Tomorrow, I will finish changing the paper and send it to you.
7/05/2017
apply the model in abernathy well and get better results
Today, I apply the model in abernathy well of BHP data and get better results.
Summary:
I discussed with Yifu. We conclude that because of high water salinity in bakken formation, the permittivity values are extremely large. But there are no logging data which can reflect this characteristic. However, the water salinity in permian basin is not high, so the prediction in abernathy well is much more accurate.
Here are the prediction performance results of abernathy well.
The first is to use original 4 con and 15 inputs to predict 4 per directly. R2 of 4 per of testing data are 0.91, 0.92, 0.80, 0.66. They are much better than that in Hess data. It shows that it is feasible to predict 4 con first and use it with logging data together to predict 4 per. But the problem is that the accuracy varies a lot.

The second is to predict 4 con first and then use predicted 4 con and logging data together to predict 4 per. At first, I predict 4 con. R2 of 4 con of testing data are 0.88, 0.87, 0.85, 0.82.

Then 4 per are predicted by 15 inputs and predicted 4 con in another ANN model. R2 of 4 per of testing data are 0.61, 0.65, 0.55, 0.51. They are more accuracy and stable than those in Hess data.
Tomorrow, I will continue to improve the prediction performance. In addition, Hao has given me part of the suggestions of improving the paper just now. I will improve it tomorrow.
Summary:
I discussed with Yifu. We conclude that because of high water salinity in bakken formation, the permittivity values are extremely large. But there are no logging data which can reflect this characteristic. However, the water salinity in permian basin is not high, so the prediction in abernathy well is much more accurate.
Here are the prediction performance results of abernathy well.
The first is to use original 4 con and 15 inputs to predict 4 per directly. R2 of 4 per of testing data are 0.91, 0.92, 0.80, 0.66. They are much better than that in Hess data. It shows that it is feasible to predict 4 con first and use it with logging data together to predict 4 per. But the problem is that the accuracy varies a lot.

The second is to predict 4 con first and then use predicted 4 con and logging data together to predict 4 per. At first, I predict 4 con. R2 of 4 con of testing data are 0.88, 0.87, 0.85, 0.82.

Then 4 per are predicted by 15 inputs and predicted 4 con in another ANN model. R2 of 4 per of testing data are 0.61, 0.65, 0.55, 0.51. They are more accuracy and stable than those in Hess data.
Tomorrow, I will continue to improve the prediction performance. In addition, Hao has given me part of the suggestions of improving the paper just now. I will improve it tomorrow.
7/04/2017
Predict magnitude and tan
Today, I predict magnitude and tan. The result is not very good.
Summary:
First, I turn 4 con and 4 per into 4 magnitude and 4 tan values. The I predict them together. The results of prediction performance are shown as follows.
The first is four magnitude. The R2 of four magnitude prediction of testing data are 0.78, 0.75, 0.71, 0.77, which are almost as good as 4 con prediction.

The second is four tan value. The R2 of four tan value prediction of testing data are 0.23, 0.24, 0.22, 0.58, which are almost as bad as 4 per prediction.

In conclusion, for now, they best method is to predict 4 con first and then use 4 con and 11 log inputs to predict 4 per.
Tomorrow, I will continue to try other methods.
Summary:
First, I turn 4 con and 4 per into 4 magnitude and 4 tan values. The I predict them together. The results of prediction performance are shown as follows.
The first is four magnitude. The R2 of four magnitude prediction of testing data are 0.78, 0.75, 0.71, 0.77, which are almost as good as 4 con prediction.

The second is four tan value. The R2 of four tan value prediction of testing data are 0.23, 0.24, 0.22, 0.58, which are almost as bad as 4 per prediction.

In conclusion, for now, they best method is to predict 4 con first and then use 4 con and 11 log inputs to predict 4 per.
Tomorrow, I will continue to try other methods.
7/03/2017
add predicted conductivity to inputs ang read more papers
Today, I add 4 predicted conductivity into 11 inputs to get better results. Also, I read some papers about how to predict dielectric data with ANN.
Summary:
If predicted conductivity are added into inputs, the prediction performance of permittivity will be improved. The following is the result of predicting permittivity. All R2 are improved. The 4 R2 of permittivity prediction are 0.12, 0.24, 0.44, 0.69. The last permittivity with the highest frequency has reached to the ideal accuracy.

In addition, I read some papers about how to predict dielectric data with ANN. For now, I have not found methods which are useful for my research.
Tomorrow, I will continue to read papers and try different methods.
Summary:
If predicted conductivity are added into inputs, the prediction performance of permittivity will be improved. The following is the result of predicting permittivity. All R2 are improved. The 4 R2 of permittivity prediction are 0.12, 0.24, 0.44, 0.69. The last permittivity with the highest frequency has reached to the ideal accuracy.

In addition, I read some papers about how to predict dielectric data with ANN. For now, I have not found methods which are useful for my research.
Tomorrow, I will continue to read papers and try different methods.
Subscribe to:
Comments (Atom)