Codes:
# plot the RMSE values
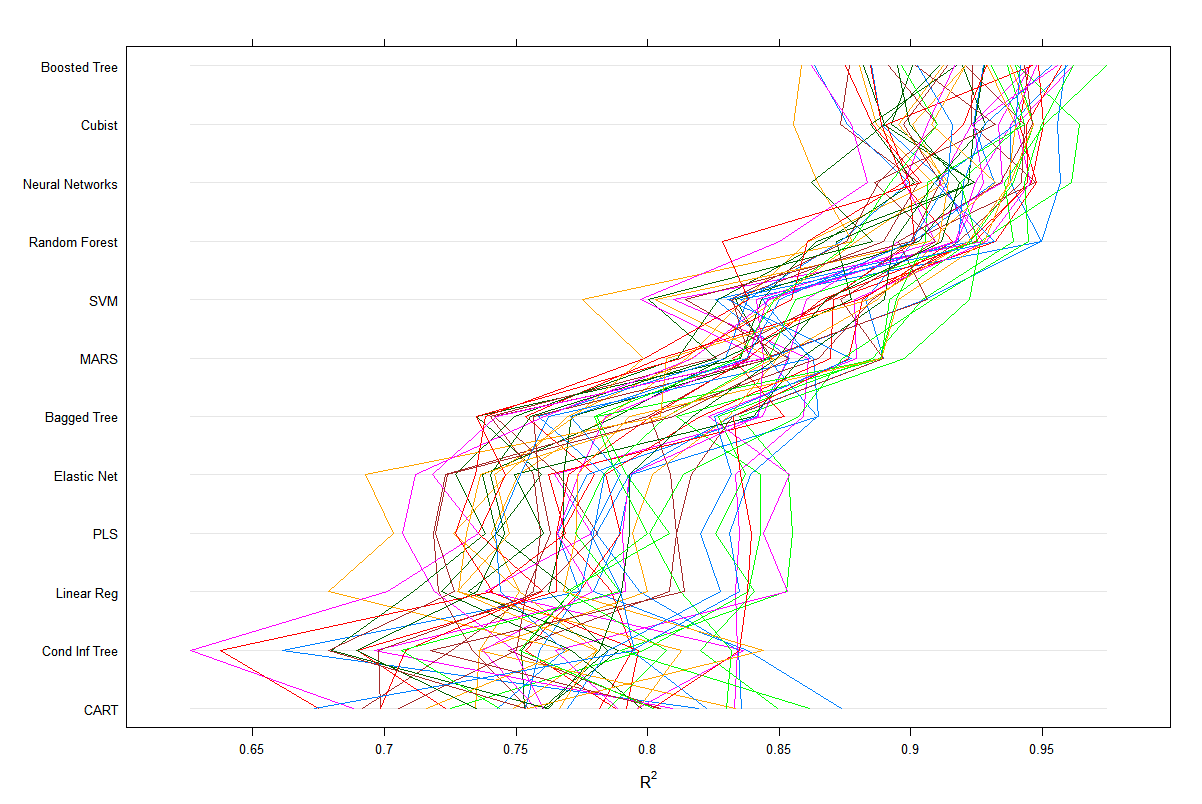
parallelplot(allresamples)
# using R2
parallelplot(allresamples, metric="Rsquared")

nnetpredictions=predict(nnetmodel, testset)
gbmpredictions=predict(gbmmodel, testset)
cbpredictions=predict(cbmodel, testset)
age28data=subset(trainingset, Age==28)
dim(age28data)
# remove the age and compressive strength columns and
# then center and scale the predictor columns
pp1=preProcess(age28data[,-(8:9)], c("center", "scale"))
scaledtrain=predict(pp1, age28data[, 1:7])
dim(scaledtrain)
# a single random mixture is selected to initialize the maximum dissimilarity sampling process
set.seed(91)
startmixture=sample(1:nrow(age28data), 1)
starters=scaledtrain[startmixture, 1:7]
#select 14 more mixtures to complete a diverse set of starting points for the search algorithms
library(proxy)
maxdis=maxDissim(starters, scaledtrain, 14)
maxdis
startpoints=c(startmixture, maxdis)
starters=age28data[startpoints, 1:7]
starters
# all seven mixture proportions should add to one
# the water proportion will be determined by the sum of the other six ingredient proportions
# remove water
startingvalues=starters[, -4]
Tomorrow, I will continue to do computing of Chapter 10.
No comments:
Post a Comment