Today, I continued to look for FMM codes. Finally, I found one of GMM example. I think it is really helpful for fitting T2 distribution.
Summary:
First, I want to point out one problem:
In distribution,
the pdf shows that y is the probability and x is the value of the variable. But
in T2 distribution, the y is the value of T2 and x is just the time.
I will try to solve it.
% $Author: ChrisMcCormick $ $Date: 2014/05/19 22:00:00 $ $Revision: 1.3 $
%%======================================================
%% STEP 1a: Generate data from two 1D distributions.
mu1 = 10; % Mean
sigma1 = 1; % Sigma
m1 = 100; % Number of points
mu2 = 20;
sigma2 = 3;
m2 = 200;
% Generate the data.
X1 = (randn(m1, 1) * sigma1) + mu1;
X2 = (randn(m2, 1) * sigma2) + mu2;
X = [X1; X2];
%%=====================================================
%% STEP 1b: Plot the data points and their pdfs.
x = [0:0.1:30];
y1 = gaussian1D(x, mu1, sigma1);
y2 = gaussian1D(x, mu2, sigma2);
hold off;
plot(x, y1, 'b-');
hold on;
plot(x, y2, 'r-');
plot(X1, zeros(size(X1)), 'bx', 'markersize', 10);
plot(X2, zeros(size(X2)), 'rx', 'markersize', 10);
set(gcf,'color','white') % White background for the figure.
%%====================================================
%% STEP 2: Choose initial values for the parameters.
% Set 'm' to the number of data points.
m = size(X, 1);
% Set 'k' to the number of clusters to find.
k = 2;
% Randomly select k data points to serve as the means.
indeces = randperm(m);
mu = zeros(1, k);
for (i = 1 : k)
mu(i) = X(indeces(i));
end
% Use the overal variance of the dataset as the initial variance for each cluster.
sigma = ones(1, k) * sqrt(var(X));
% Assign equal prior probabilities to each cluster.
phi = ones(1, k) * (1 / k)
%%===================================================
%% STEP 3: Run Expectation Maximization
% Matrix to hold the probability that each data point belongs to each cluster.
% One row per data point, one column per cluster.
W = zeros(m, k);
% Loop until convergence.
for (iter = 1:1000)
fprintf(' EM Iteration %d\n', iter);
%%===============================================
%% STEP 3a: Expectation
%
% Calculate the probability for each data point for each distribution.
% Matrix to hold the pdf value for each every data point for every cluster.
% One row per data point, one column per cluster.
pdf = zeros(m, k);
% For each cluster...
for (j = 1 : k)
% Evaluate the Gaussian for all data points for cluster 'j'.
pdf(:, j) = gaussian1D(X, mu(j), sigma(j));
end
% Multiply each pdf value by the prior probability for each cluster.
% pdf [m x k]
% phi [1 x k]
% pdf_w [m x k]
pdf_w = bsxfun(@times, pdf, phi);
% Divide the weighted probabilities by the sum of weighted probabilities for each cluster.
% sum(pdf_w, 2) -- sum over the clusters.
W = bsxfun(@rdivide, pdf_w, sum(pdf_w, 2));
%%===============================================
%% STEP 3b: Maximization
%%
%% Calculate the probability for each data point for each distribution.
% Store the previous means so we can check for convergence.
prevMu = mu;
% For each of the clusters...
for (j = 1 : k)
% Calculate the prior probability for cluster 'j'.
phi(j) = mean(W(:, j));
% Calculate the new mean for cluster 'j' by taking the weighted
% average of *all* data points.
mu(j) = weightedAverage(W(:, j), X);
% Calculate the variance for cluster 'j' by taking the weighted
% average of the squared differences from the mean for all data
% points.
variance = weightedAverage(W(:, j), (X - mu(j)).^2);
% Calculate sigma by taking the square root of the variance.
sigma(j) = sqrt(variance);
end
% Check for convergence.
% Comparing floating point values for equality is generally a bad idea, but
% it seems to be working fine.
if (mu == prevMu)
break
end
% End of Expectation Maximization loop.
end
%%=====================================================
%% STEP 4: Plot the data points and their estimated pdfs.
x = [0:0.1:30];
y1 = gaussian1D(x, mu(1), sigma(1));
y2 = gaussian1D(x, mu(2), sigma(2));
% Plot over the existing figure, using black lines for the estimated pdfs.
plot(x, y1, 'k-');
plot(x, y2, 'k-');
I think it is the most suitable example close to my research.
Tomorrow, I will continue to look into it.
























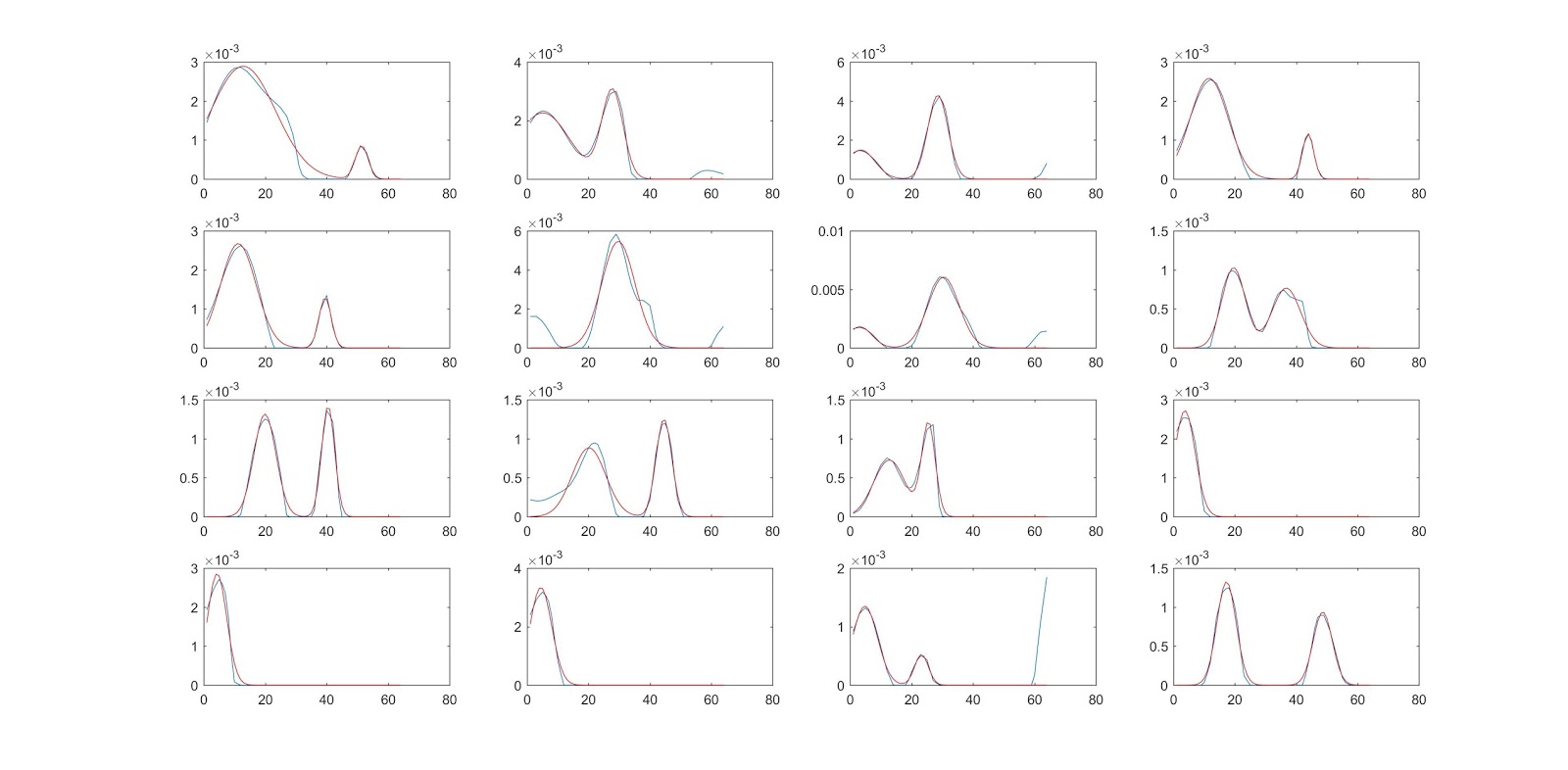


 These are the first 16 depths to be fitted. Most of them are really good. Most of their R2 is larger than 0.9. However, some of them are not good.
These are the first 16 depths to be fitted. Most of them are really good. Most of their R2 is larger than 0.9. However, some of them are not good.








